|
|
 |
||||||||||||||||||||||||||||||||||
PDFファイルをWordやExcel形式に変換! 「いきなりPDF to Data」 |
||||||||||||||||||||||||||||||||||
|
いま、PDF作成ソフトが熱い。以前紹介した「いきなりPDF Professional」の新バージョン「いきなりPDF Professional 2」などの低価格ソフトに加え、本家本元であるアドビシステムズからも低価格版の「Acrobat Elements」が発売されたことにより、PDF作成ソフトは文字通り百花繚乱という状況である。 そんなPDF作成ソフトの中で、いま密かに注目を集めるのが、PDFを修正・加工する機能を持ったソフトである。もともとPDFというフォーマット自体、改ざん防止を目的として導入されるケースが多く、ページ単位の削除・挿入ならまだしも、本文そのものを加工・修正することは想定されていない。しかし、PDFという形式がビジネス分野で幅広く用いられ、誰もが利用するようになった現在、「作成済みのPDFを手軽に加工・修正したい」というニーズが出てくることは、なんら不思議なことではない。 今回紹介するソースネクストの「いきなりPDF to Data」は、そんなPDFデータを編集可能にするためのPDF作成ソフトだ。正確にはPDF作成ソフトではなく、PDF解析ソフトと言ったほうが良いだろう。
■ OCR機能で文字認識し、PDFをWord文書に変換
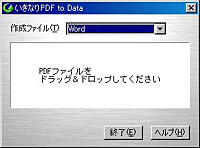
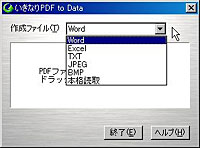
もう1つは、OCR機能を利用することで、PDF内で画像として扱われている文字もテキストデータとして「文字認識」するタイプだ。今回紹介する「いきなりPDF to Data」は、このOCR機能を備えたタイプで、PDF内にテキストデータとして文字が保存されていない場合でも、編集可能となることが特徴である。 それでは、早速使ってみよう。まず、「いきなりPDF to Data」を起動すると、ダイアログボックスが表示される。ここに任意のPDFをドラッグ&ドロップすると、元のPDFと同じ階層にPDFの名前がついたフォルダが生成される。その中にWord文書など編集・加工可能な形式のファイルが生成される、というわけである。 生成するファイルの形式は、「Word」「Excel」「TXT」「JPEG」「BMP」「本格読取」の6種類から指定できる(デフォルトはWord形式)。手動で設定しなくてはいけない項目はこれだけで、あとはドラッグ&ドロップするだけで、いとも簡単に生成作業は完了する。変換に必要な時間は、元のPDFファイルのページ数やレイアウトの複雑さに比例するが、だいたい1ページあたり数秒~数十秒と考えれば良いだろう。 なお、PDFの読み込み元がCD-ROMなど、書き込みができない領域の場合、いったんデスクトップなど書き込み可能な場所にPDFをコピーしてから作業をする必要がある。また、本製品は仮想プリンタ機能を利用するため、PDFのセキュリティオプションで「印刷不可」が指定されている場合は利用することができないので注意が必要だ。 ■ どのくらい正確に元文書を再現できるのか?
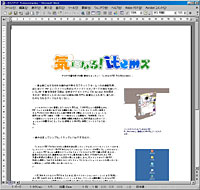
まず、テキストと図版が混在したWord文書のオリジナルを作成し、「いきなりPDF Professional 2」を用いていったんPDFに変換。それをさらに「いきなりPDF to Data」でWord文書に再変換する。つまり、 ・オリジナルのWord文書「A」 ・Aから生成したPDF「B」 ・Bから本製品経由で生成したWord文書「C」 の3つを作成し、最終的に生成された「C」が、オリジナルの「A」をどの程度再現しているかを確かめようという実験である。
詳細は画面写真をご覧いただければと思うが、レイアウトこそオリジナルの文書が維持されているものの、全体のイメージはオリジナルとは大きく異なっている。テキストそのものはおおむね誤字もなく認識されているが、図版の一部をテキストデータとして認識しようとした形跡があるほか、フォントの種類やサイズといった属性がバラバラで、1枚の文書としては見られたものではない。
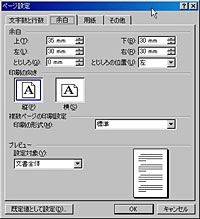
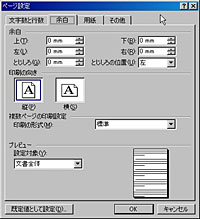
また、生成されたWord文書で、ページ設定の上下左右の余白がいずれも「0」になるのも気になるところだ。確かに「Wordで開けるdoc形式の文書」が生成できるとはいえ、Wordデフォルトの設定で作成される文書とは体裁が大きく異なる。本製品で生成したWord文書を、一般的なWord文書と同列に扱うことは難しいと見たほうがよさそうだ。 変換精度については元のPDFのクオリティにも影響されるはずなので、どんなPDFでもこのような状態になるとは言い切れないが、本製品を使って手元のPDFをコッソリ修正し、元ファイルと見分けがつかないレベルのPDFに再出力して配布する、といったことは現実的に不可能と考えたほうが良いようだ。PDF作成時のオリジナルファイルが手元に残っているなら、そちらを修正してPDFを再出力するのが大原則だろう。 ただ、PDF作成時のオリジナルファイルを紛失してしまっている場合や、他人から入手したPDFを加工したい場合は、本ソフトを利用するメリットが大きい。特に、何十ページもあるようなPDFからテキストを抜き書きしたい場合、キーボードから手入力で復元するのは困難だ。このような場合、本製品を使っていったんテキストデータに起こし、あとからOCRのミスを拾って手作業で修正していくようにすれば、作業時間は大幅に節約できるはずだ。
■ 元のテキストデータは用いず、ページごとOCRで認識 前述の実験では、テキストデータを内部に含んだPDFを用いたので、OCR機能がきちんと働いたかどうかは分からない。PDFに含まれているテキストデータを抽出したのか、それともOCRで文字認識をしたのか、これだけでは判断がつかないのである。そこでもう1つ、以下のような実験を行なうことにした。まず、用意したPDFをAbobe Illustratorで開き、テキストデータをすべてアウトライン化して再保存。これを「いきなりPDF to Data」でWord文書に変換する。また同時に、元のPDFについても別途「いきなりPDF to Data」でWord文書に変換する。つまり、 ・テキストデータが含まれたPDFから本製品経由で生成したWord文書「D」 ・テキストデータをアウトライン化したPDFから本製品経由で生成したWord文書「E」 の2つを比較し、テキストの認識具合を確認しようというものである。
結論から言うと、この2つのPDFから生成されたWord文書は、それほど文字認識に大きな差は見られなかった。その一方で、テキストデータが含まれたPDFから生成したWord文書で文字化けが発生したことから、本ソフトではPDF全体を1枚の画像としてOCRで一括処理していると考えられる。だとすれば、PDFにテキストデータが含まれているのに文字化けしたことも理解できるし、図版の一部がテキストデータに置換されて配置されていることも説明がつく。 恐らく本ソフトでは、まずPDF読込時にページ全体のレイアウトを作成し、そこにテキストボックスやExcelでいうところのセルを配置し、最後にOCR処理を行なってデータを貼り付けているのだと思われる。この際、図版についてもOCR処理が行なわれるため、図版の内容によってはアスキーアートのような文字がペタペタと貼り付けられ、図版そのものが存在しなくなるという妙な状態になってしまうのだ。 本ソフトによるWord文書の生成で大きな問題があるとすれば、恐らくこの部分だろう。テキストデータは誤っていれば手入力で修正することができるが、図版がOCRによって無理矢理文字に変換され、元の図版が失なわれてしまっては、別のアプリケーションでオリジナルの図版を抽出して貼り付けない限り、修正のしようがない。せめてOCR処理を実行する前に元データを解析してテキスト領域と図版領域に分け、それぞれについて最適な処理が行なえないものだろうか。 ■ TXTやJPEG出力は便利。使い方はユーザーの工夫次第 資料として入手したPDFに書かれた内容、特に表データを抽出して再利用する場合、何よりも正確性が重視されるはずだ。本製品でPDFをExcelファイルに変換した場合、細部の文字がそのまま使えることは(よほど解像度が高くない限り)まずあり得ない。そのため、抽出したテキストデータをそのまま使ったり、数字を計算して統計を出すなど、信頼性を求められる用途に使う場合は十分に注意することをお勧めする。“0(ゼロ)”が“O(オー)”と認識されたり、余計なスペースが挿入されたことで、計算結果に差異が生じるといったリスクがあることも十分に理解しておきたいところだ。
一部のOCRソフトには、文字列をクリックするとオリジナル画像のどの範囲を認識したかが枠で表示され、再認識などの作業を簡単に行なえる製品がある。本製品はドラッグ&ドロップで出力というシンプルな操作性のため、こういった再認識作業は行なえない。姉妹品の「本格読取」と組み合わせることで認識精度を高める方法もあるらしいが、本製品単体で使う場合は、もとのPDFのクオリティがすべてを決める、といっても過言ではなさそうだ。 最後になったが、本製品を試用してみて、個人的に「これは使える!」と感じたのは、むしろ出力形式が「TXT」「JPEG」の場合だ。「TXT」「JPEG」でテキストデータと画像データを別々に生成し、それらを加工して合体させたほうが、信頼性の高いWord文書が作成できる。もちろんレイアウトを自力で行なったり、目的の画像を別途ソフトで切り出す作業は必要だが、手のほどこしようがないWord文書を抱えてストレスを溜めるよりはよほどマシだ。オリジナルのレイアウトを完全に再現するのが目的ではなく、素材として再利用するだけなら、こちらのほうがよっぽど効率が良いだろう。このあたりはユーザーの工夫次第だと言えそうである。
「PDFを読み取り、WordやExcelなどの書類として出力できる」という本製品のコピーは広告としては非常に効果的だと思われるが、中途半端な機能でユーザーをがっかりさせるよりは「PDFに含まれるテキストや画像をかんたんに抽出できるソフト」としたほうが、本製品の特性を端的に表しているように感じる。ともあれ、着眼点が優れたソフトウェアであることは間違いないので、今後ますますの発展を期待したい。 ■ URL 製品情報 http://www.sourcenext.com/products/pdf_todata/ ソースネクスト http://www.sourcenext.com/ ■ 関連記事 ・ PDF文書作成や分割・結合もカンタン!「いきなりPDF Professional」 (後藤重治) 2005/08/03 11:04 |








| Broadband Watch ホームページ |
| Copyright (c) 2005 Impress Watch Corporation, an Impress Group company. All rights reserved. |