 |
|||||||
その110「文字コードとは」 |
|||||||
|
■ 文字コードって何? PCに限らずコンピュータは一般に、文字を文字として扱うことはできません。そこで、文字に番号を付けて対応を行なっており、この番号のことを「文字コード」と呼びます。文字コードとして昔から使われてきたものには、「ASCIIコード」や「EBCDICコード」、最近では「ISO-8859」などが世界的に使われています。また、日本に限って言えば、「JIS X 0208/0212/0213」という、いわゆる「JIS漢字」が古くから使われてきましたが、これを表現するための符号化方式として「ISO-2022-JP/Shift JIS/EUC」などが組み合わされて使われていたほか、最近はUnicodeも広く利用されるようになってきました。 問題は、これらの文字コードが「大雑把には相互変換可能」、逆に言えば「細かい非互換部分が残されている」という点でしょう。 ■ 文字集合と符号化方式
図1は、ASCIIコードとEBCDICコードを比較したものです。ASCII/EBCDICのどちらも、基本的には数字とアルファベット、いくつか記号を表現するためのものです。例としてこの中でA~Tまでの20文字を並べてみました。しかし、ここでは「表示される文字はどちらも同じA~T」ですが、「それを示すコードはまったく別々」という風になっています。 では、コードが同じならば常に同じ文字が表示されるかというと、そうではありません。代表例の1つが、「ISO/IEC 8859」というコード体系です。名前の通り、ISOで標準化されたものですが、こちらはISO/IEC 8859-1~8859-16まで、16通りのコードが用意されています。 ISO/IEC8859自体は、ASCIIコードを拡張したものです。ASCIIコードが0x00~0x7Fまでしか定義されていないので、その後の0x80~0xFFまでに割り当てたものですが、ISO/IEC 8859-1はLatin 1(西欧語圏向け)、ISO/IEC 8859-2はLatin 2(中央・東欧語圏向け)、ISO/IEC 8859-3はエスぺランド語やトルコ語向け……という具合に、使用する言語に応じて細かく分けられています。これらを使うと、文字コードは同じでも、どの文字種を使うかで表示される文字が変わってしまうというわけです。
■ 文字コードの問題
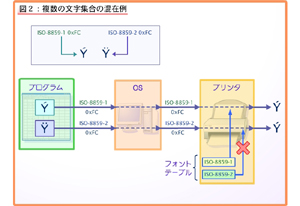
実際、こうした機能をウリにしているワードプロセッサもいくつかあったほどです。これらの大半は、文字単位で「それがどの文字集合に属する文字か」を別に保持しておくことで、複数言語への対応を図っていました。ただ、プログラムの内部でこれを保持するのは簡単でも、それを表示する、印刷するといった処理の場合にはしばしば困難が生じました。 というのも、ディスプレイアダプタやプリンタは通常、1つの文字集合を使って表示、あるいは印刷することを前提としていたからで、複数の文字集合が入り混じると正しく表示/印刷できないというケースも見受けられました。これを解決するために表示、印刷はBMPで出力する手法が用いられていました。ちょっと実例を示してみましょう。 ISO-8859-1で0xFCには“Y”という文字が割り当てられていますが、ISO-8859-2では“?”になっています。そこでこの2文字を連続して表示したいと思った場合を考えます。プログラムには、2つの文字がそれぞれ個別に格納されており、これを印刷したいと思った場合、プログラムはOSに対し、それぞれの文字コード種別(文字集合)と実際のコードを送り、OSはこれをそのままプリンタに送ります。 問題はプリンタの内部です。プリンタは各文字集合に対応したフォントテーブルを持ち合わせており、各々の文字集合を最初に送ると、それに合わせたフォントを選び、実際に印字を行なうわけですが、文字ごとにフォントを切り替えるという機能を持たないプリンタも少なくありませんでした。この結果、2文字目は本当はISO-8859-2にも関わらず、ISO-8859-1のフォントが使用され、1文字目と2文字目に同じ文字が印字されてしまうということになります。 これを避けるために、プログラムからOSに文字コードを送るのではなく、“Y”や“?”という形のBMPをOSに送り、OSはこれをBMPとしてプリンタに送るというのが当時の解決法でした。こちらはどんな環境でも使えるという点で便利なのですが、プログラムが持っているフォントしか使えないといった制約もあるほか、根本的な解決になっていない(すべてのプログラムが自前で処理する必要がある)点も問題視されていました。 こうした問題を解決するために登場したのがUnicodeです。要するに、8bit(最大256文字)で文字を表現しようとするから無理がある、という認識のもとに、文字サイズを16bit(=最大65536文字)まで広げることで、すべての文字を網羅しようという試みでした。ところがこの案は早々に破綻しました。理由は簡単で、16bitではすべての文字が入りきらなかったからです。結果、Unicodeを拡張し、一部の文字は32bit化(Unicode2つで1文字を示す)して、最終的には111万文字あまりの領域を確保することで、対応が取れるようになりました。このUnicodeのコード体系を示すものに、「UTF(Unicode Transformation Format)」があります。主要なものとしては、以下のようになります。 ・UTF-8 8bit単位でUnicodeのコードを表現する。結果、1文字を示すのに1/2/4バイトの3パターンがあり、プログラムの処理は複雑化する。反面、データを1番節約しやすい。 ・UTF-16 16bit単位でコードを表現。最近はこのUTF-16が次第に普及してきている。 ・UTF-32 32bit単位でコードを表現。プログラムの処理は1番すっきりする反面、データ量は大きくなりやすい インターネットの世界においても、Unicodeは次第に普及しており、エンコードにUTF-8のオプションが標準で入ってくるようになりました(写真01)。まだ若干問題は残るものの、こと文字集合の混在に関してはUnicodeを使うことで一応の解決を見たというのが欧米における一般的な認識と言って良いでしょう。 ■ 日本における文字コードの問題
このJIS X 0208は文字集合なわけですが、これに対応する符号化方式がまず混乱していました。インターネットやPC(MS-DOS)が普及する前から、コンピュータメーカー各社が独自の符号化方式で、JIS X 0208を取り扱えるようにしていました。 この時の符号化方式は、JIS X 0208に割り当てられていたコードをベースにしつつも、各メーカーが独自拡張が行なわれていた関係で、微妙に互換性がないという状況でした。それでもここまではJIS X 0208を大きく逸脱することはなかったのですが、状況が変わってきたのは、MicrosoftがMS-DOSの日本語化を行なった(*1)際に、Shift_JISと呼ばれる新しいコードを導入してからです。 Shift-JISは、ASCIIコードと両立するような形にコード体系を変更しており、海外で動作していたプログラムを日本語環境でそのまま動作させられるメリットを持っています。そして、MS-DOSやその後継であるWindows、一部のUNIXマシンなどで広範で使われる符号化方式として定着しており、その後に「JIS X 0208:1997」で公式に「シフト符号化表現」として仕様が定義されました。そしてその後には、「JIS X 0213」において「Shift_JISX0213」として標準規格としてのポジションを確立します。 さらに、「EUC-JP(Extended Unix Code)」と呼ばれる符号化方式も登場します。名前からもわかる通り、UNIXで利用されるための符号化方式で、規格を定めたのはAT&Tです。“-JP”という名前が語尾にあるのは、EUC自体はUNIXの多言語拡張を目指したもので、この日本語バージョンがEUC-JPという位置付けになります。 この3種類、つまりJIS X 0208もしくはその拡張版(これを「JIS漢字コード」と称するのが一般的)とShift_JIS、EUC-JPの符号化方式が一般に混在するという状況になりました。また、これに輪をかけているのが、文字集合の変遷です。先に述べたように基準になるのはJIS X 0208ですが、これ自体も以下のように4種類が存在します。 ・1978年に登場した6,802文字(JIS C 6226-1978) ・1983年に登場した6,877文字(JIS C 6226-1983/JIS X 0208-1983) ・1990年に登場した6,877文字(JIS X 0202-1991) ・1997年に登場した6,879文字(JIS X 0208-1997) 一見、JIS X 0208-1983以降は大きな違いはないように思えるのですが、文字の入れ替えや例示字形の変更などが毎回行なわれたりもしました。また、JIS X 0208を補完する目的で「JIS X 0212」という補助漢字集合が1990年に制定されますが、このShift_JISではJIS X 0212が使えないという問題があり、これへの対応として「JIS X 0213」という新たな文字集合が2000年に登場(JIS X 0213-2000)、2004年に改定されています(JIS X 0213-2004)。JIS X 0213自体は、JIS X 0208-1997をベースに補助漢字などを大きく追加しもので、総文字数は11,223文字に達します。 これだけ文字集合が多いと、当然対応にも苦慮せざるを得ません。符号化方式の側にとっても、例えば「JIS X 0208に対応したShift_JIS」と言っても、それがどのJIS X 0208なのかによって文字が変わってきてしまうわけで、個別対応が結局必要になってしまいます。 一般にはこうした対応はOSによって変わってくるのが一般的です。例えば、Mac OS XはJIS X 0213-2000を、Windows XPではJIS X 0208-1997をベースとしています。どちらのOSも内部的にはUnicodeで表現していますが(Mac OS XはUTF-16、Windows XPはUTF-8と聞いています)、ファイルなどの書き出しにはShift_JISを使っています。これにより起きている現象が、続に言われる「機種依存文字」問題です。一見どちらも符号化方式はShift_JISですから共通に見えるのですが、文字集合が異なっていますから、同じ文字が表示されるとは限りません。 例えば、Windows XPの上で“III(ギリシャ数字の3)”という文字を使うと、Mac OS上では“(企)(括弧付きの「企」)”という文字に化けてしまいます。これはインターネットの世界でも起きている話で、結果として「Webページを作るときには、なるべく機種依存文字を使わないようにしましょう」といった啓蒙をよく見かけます。 この問題は、両方のOSが扱う文字集合が違っているためですが、どちらのOSも開発時点で最新に近い規格をベースに設計されている以上、この違いを責めるわけにはいきません。最近はこれに携帯電話まで加わり、話はさらに難しくなっています。携帯電話は絵文字などを独自に拡張するケースが多く、しかも、インターネットアクセス可能な端末が増えてきた結果、掲示板などの書き込みに「その携帯電話事業者や端末でしか正しく表示されない」文字が大量に登場し始めているのが現状です。 この問題は根が深く、しかも解決が難しいものです。登場したてのWindows VistaはJIS X 0213をベースとしたものに生まれ変わったので問題は大分解決するかのように見えますが、こちらはJIS X 0213-2004がベースなので、依然としてMac OSと完全にコードが一致しているわけではありません。また、この先にJIS X 0213で新たな拡張や、新しい漢字コードの登場なども皆無ではないので、そうした場合には新たな火種がまた生まれることになります。 また、世の中のすべてのマシンをWindows VistaとMac OS Xで置き換えられるわけではなく、古い機種も多く残ったままですから、これらとのコード非互換性は残ったままですし、携帯電話に関しても同様でしょう。根本的には、日本語の文字があまりに多様性に富みすぎていて、コード化が難しいということに尽きるでしょう。もちろんこれはIT関係者から見た視点であって、日本語関係者からすれば「多様性のある日本語を無理に押し込めようとすることに問題がある」という意見もありそうですし、簡単に収束する議論にも思えません。とりあえずユーザーとしては、さまざまな文字集合で共通するコードのみを使って運用する、というのが1番賢明な策なのでしょう。 なお、余談になりますが、この日本語の文字コードの問題に関しては、Internet Watchで小形克宏氏が連載されている「文字の海、ビットの舟」で非常に詳しく論じておられます。興味のある方はこちらを一読することをお勧めします。 *1:正確に書けば、三菱電機が同社のMulti16という16bitパソコンにDigital Research社のCP/M-86というOSを日本語化して搭載する際に開発され、それをMS-DOSでも継承したという形になります。ただこの日本語化作業をどの会社が担当したかについては、諸説あります。 2007/02/05 11:01
|



| Broadband Watch ホームページ |
| Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved. |